

Last Updated on: 21st November 2023, 08:14 pm
We are living in a world where common problems are being faced head-on and solutions are being found and shared with the world every day.
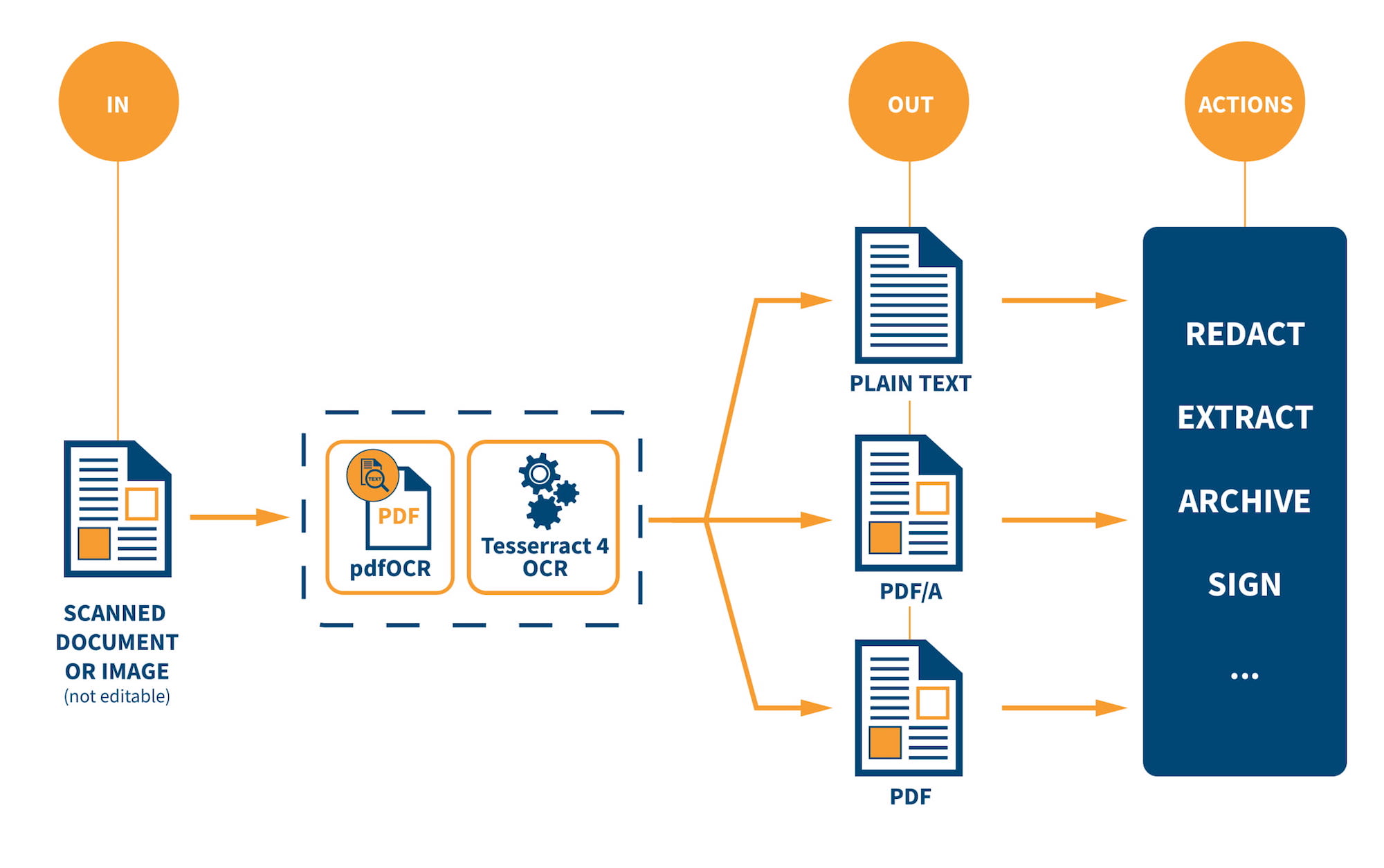
One such solution comes in the form of an open-source product which enables text recognition of scanned documents and converts them into editable formats.
This product is called the iText pdfOCR.
It has been developed by iText Group NV, a group that continues to innovate with its PDF software solutions.
The product engages in Optical Character Recognition, a function that converts scanned documents into searchable PDF formats. It is expected to be a game changer for administrative tasks, as it provides the possibility of cataloguing scanned documents to be searched, indexed and even interpreted.
Multilingual document recreation with the iText pdfOCR will be a possibility thanks to it working alongside Tesseract OCR engine technology – a tool which supports over 100 languages.
Yeonsu Kim, CEO at iText Group NV, discussed its potential, stating:“With COVID-19 urging companies to accelerate their digital transformation projects, organizations are forced to explore new ways of accessing and managing their data – existing and new.”
The CEO added: “Being a leader in the digital documents space, we’re pleased to be at the forefront of this new era.
“As such, I am very proud to announce the latest addition to our PDF library for today’s new world: thanks to the OCR capabilities of iText pdfOCR many new opportunities will open up for users and enterprises that want to maximize their data potential.”
Please tune in for live demos on 9 July 2020. More information can be found here.